
Was ist Machine Learning? – Und wieso gewinnt maschinelles Lernen immer mehr an Bedeutung? – Die Funktionsweise erklärt anhand eines Beispiels, dazu ein Blick auf die Chancen und Risiken.

(Bild: IBAW)
Wir alle lernen tagtäglich Neues und wenden es in unserem Leben an. Doch was bedeutet es, wenn eine Maschine lernen kann? Und was braucht es dazu? Um die Begriffe Machine Learning (ML) und künstliche Intelligenz (KI, bzw. englisch Artificial Intelligence; AI) kommt heute niemand mehr herum. Selbst wer die Ausdrücke nicht kennt, begegnet den lernenden Maschinen im Alltag - und das ständig. Etwa, wer online nach einem Produkt sucht.
Der Online-Shop lernt aus unseren Daten, welche Produkte uns auch noch interessieren könnten, und schlägt sie vor. Streaming-Dienste lernen aus unserem Verhalten, welche Musik oder Filme wir mögen. Und bei jeder Kreditkartenzahlung lernt ein Programm, unser Kaufverhalten besser zu verstehen, so dass es Betrugsversuche erkennt.
(Bild: IBAW)
Lernen ist untrennbar mit Erfahrung verbunden – und deshalb auch mit dem Gedächtnis. Unser Gehirn schafft es, wichtige Elemente aus vergangenen Ereignissen zu extrahieren und so bereitzustellen, dass wir beim nächsten Mal in einer ähnlichen Situation besser handeln können. So lernen wir laufend dazu. Doch was bedeutet in diesem Fall «besser handeln»?
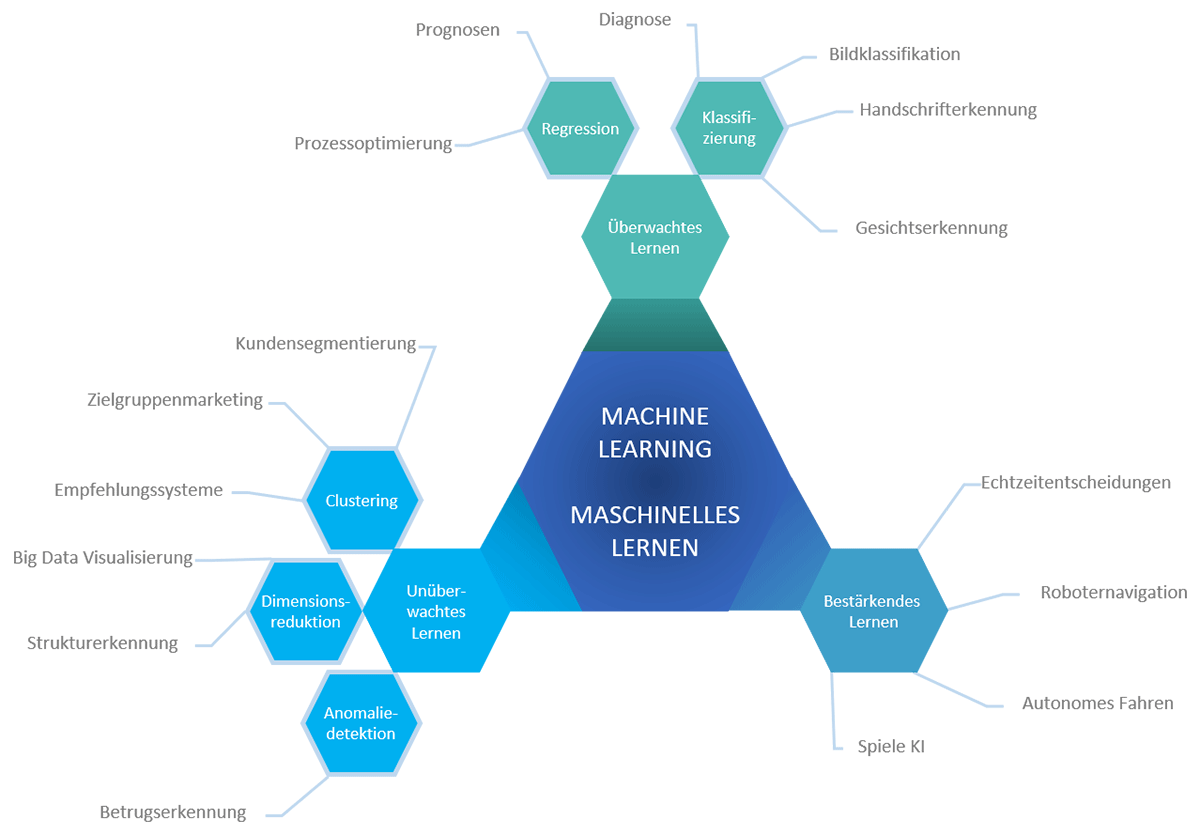
In unserem Lernprozess kann eine Fachperson die Qualität von Lösungen beurteilen und so unseren Fortschritt überwachen. Beim ML spricht man hierbei von überwachtem Lernen (engl. Supervised Learning). Wir lernen aber auch durch Anreiz oder Bestrafung, zum Beispiel durch Schmerzen bei einer sportlichen Aktivität, dass ein Vorgehen dem anderen überlegen ist. Dies nennt sich bestärkendes Lernen (engl. Reinforcement Learning). Bei der dritten Art des Lernens, dem unüberwachten Lernen (engl. Unsupervised Learning), geht es um die Kategorisierung von Dingen, von denen wir nur gewisse Merkmale kennen. Dabei erstellen wir ohne äussere Vorgaben Kategorien, denen sich die untersuchten Dinge möglichst eindeutig zuordnen lassen.
Statt Gedächtnis: ein Algorithmus
Was beim Menschen das Gedächtnis übernimmt, macht beim ML der Algorithmus. Erfahrungen sammelt er, indem er mit grossen Datenmengen in guter Qualität versorgt wird. Daten sind der zentrale Wertstoff, der die erfolgreiche Anwendung von ML überhaupt möglich macht.
Und darin liegt auch einer der Gründe, weshalb die Bedeutung von ML gerade in den letzten Jahren so stark gewachsen ist: Durch die Digitalisierung liegen unglaublich viele Daten in digitaler Form vor und können für neue Anwendungen des Lernens eingesetzt werden.
Eine der grössten Herausforderungen ist es, die richtigen Daten in genügender Qualität und Menge zur Verfügung zu haben. In dieser Disziplin sind die grossen Tech-Giganten wie Google, Facebook und Co. besonders stark, da sie mit ihren Hauptgeschäften vor allem eines tun: Daten sammeln.

Ein Auszug aus der MNIST-Datenbank: Die handgeschriebene Zahl jeweils als Bild, darunter das entsprechende Label. https://de.wikipedia.org/wiki/MNIST-Datenbank
Supervised Learning, so lernen Maschinen
Beim überwachten Lernen übergibt man einem Programm eine grosse Anzahl von Aufgabenstellungen und dazu die korrekten Lösungen, die sogenannten Labels. Das Programm wird mit diesen Daten trainiert, bis es gelernt hat, die Labels möglichst gut aus den Daten herzuleiten. Anschliessend wird das trainierte Programm auf neue, bisher ungesehene Aufgabenstellungen angewendet.
Ein bekanntes Beispiel dafür ist die Erkennung handgeschriebener Ziffern (siehe Bild Auszug MNIST-Datenbank). Die Trainingsdaten bestehen hier aus einer grossen Zahl von Bildern handgeschriebener Ziffern (Aufgabestellung) und den darin dargestellten Zahlenwerten (Labels).
Das Ziel ist die Erstellung eines Programms, das ein Bild entgegennimmt und daraus das korrekte Label berechnet. Wie das Programm diese Berechnung vorzunehmen hat, ist dabei nicht vorgegeben, das lernt es selbständig aus den Trainingsdaten.
Um zu verstehen, was es bedeutet, dass ein Computerprogramm lernt, hilft der mathematische Begriff der Funktion. Eine Funktion beschreibt ein Verfahren, wie aus einem oder mehreren Eingabewerten ein Resultat berechnet werden kann. Ein bekanntes Beispiel ist die quadratische Funktion, die durch folgende Formel gegeben ist:
f(x)=ax²+bx+c
x ist der Eingabewert der Funktion f. Damit sich die Funktion berechnen lässt, müssen die drei Parameter a, b und c festgelegt werden. Jede unterschiedliche Wahl der drei Parameter definiert dabei eine andere Funktion.
Ein Modell im Machine Learning ist nichts anderes als eine solche Funktion, die als Eingabewert die Aufgabenstellung entgegennimmt und als Resultat die gewünschte Lösung zurückgibt. Die Aufgabe des Data Scientists ist es, aus der Vielzahl verfügbarer Modelle eines auszuwählen, das sich für die Problemstellung eignet.
Für die Texterkennung hat sich als Modell ein künstliches neuronales Netz bewährt. Als Eingabewerte übergibt man die Graustufen aller Pixel des Bilds. Das Resultat der Funktion ist jeweils eine ganze Zahl zwischen 0 und 9.
Im Training berechnet das Programm die Funktion für viele verschiedene Werte der Parameter und wählt am Ende die Werte aus, die für die Trainingsdaten die besten Ergebnisse liefern. Im vorliegenden Beispiel werden also die Werte ausgewählt, mit denen der grösste Anteil der Ziffern korrekt erkannt wird.
Eine Herausforderung des überwachten Lernens ist die Bereitstellung der Trainingsdaten. Da vor dem Training noch kein Modell existiert, das die Aufgabenstellungen in den Daten mit Labels versehen könnte, muss diese Arbeit meist von Menschen gemacht werden.
Für dieses Labelling werden Fachkräfte benötigt, die das erforderliche Domänenwissen mitbringen. Geht es etwa um die Diagnose von Tumoren in medizinischen Bildern, müssen Ärzte für tausende Bilder eine Diagnose erstellen, um das Programm mit Trainingsdaten zu versorgen. Dieser Schritt ist aufwendig und teuer.
I'm not a robot
Eine kreative Methode zum Labeln von Trainingsdaten haben Forschende der Carnegie Mellon University 2008 gefunden.1
Bereits damals verwendeten viele Webseiten sogenannte Captchas, um maschinellen Zugriff aufzudecken und zu verhindern: Die Seite fordert die User auf, ein Wort abzutippen, das in einem Bild verzerrt dargestellt ist. Das Wort ist für Computerprogramme nur schwer lesbar, während die meisten Menschen den Test erfolgreich bestehen.
Als Alternative zu verzerrten Wörtern verwendeten die Forschenden Bilder von Wörtern, die bei der automatischen Digitalisierung von Büchern vom System nicht identifiziert werden konnten. So erfüllt dieser Test eine Doppelrolle: Er schützt Webseiten vor dem Zugriff durch Roboter und verwendet gleichzeitig die Arbeitskraft der User, um ein ML-Modell zu unterstützen.
Dank dieser Idee ist es nicht mehr nötig, die Arbeit für das Labelling extra zu bezahlen. Das funktioniert allerdings nur für Aufgabenstellungen, die für Menschen ohne besondere Vorkenntnisse lösbar sind und lässt sich nicht für die erwähnten medizinischen Bilder einsetzen.>
Risiken und gesellschaftliche Herausforderungen
Dass dem ML-Modell nicht vorgegeben wird, wie es die Problemlösung angehen soll, bedeutet zugleich, dass der Entwickler des Modells gar nicht weiss, wie sein Programm arbeitet. Dadurch kommen zu den bekannten Aspekten des Datenschutzes sowie dem Schutz der Privatsphäre eine Reihe ethischer Schwierigkeiten.
Es stellt sich etwa die Frage, wie viel Entscheidungskompetenz man einem Programm überlassen will, das seine Entscheidungen aufgrund nicht nachvollziehbarer Kriterien trifft.
Schlägt eine Maschine vor, welchen Film man als nächstes schauen könnte, mag eine fehlerhafte Entscheidung ärgerlich sein, aber harmlos. Anders sieht es aus, wenn eine Maschine entscheidet, ob ein Auto bremst. Oder ob eine Drohne das Ziel angreifen und zerstören soll.
Diese und ähnliche Fragen werden glücklicherweise zunehmend von Behörden und Ethikkommissionen aufgegriffen. In Zukunft wird es sicherlich Gesetze geben, die den Umgang mit maschinellem Lernen regeln, wie es sie für den Datenschutz bereits gibt. Aber die Gesetzgebung wird der rasanten Entwicklung der Technologie wohl stets hinterherhinken.
Deshalb ist es umso wichtiger, verantwortungsvoll mit Daten umzugehen – auch mit den eigenen. Das wird allerdings immer schwieriger, wenn man sich den neuen Technologien nicht ganz verweigern will.
Studieren am IBAW
Der Nachdiplomkurs Data Science setzt auf die Arbeit mit konkreten Anwendungen aus der Praxis. So ermöglicht er einen raschen und fundierten Einstieg in die Datenanalyse und in Machine Learning.
Publikation in Zusammenarbeit mit

VIW – Wirtschaftsinformatik Schweiz
www.viw.ch | T +41 31 311 99 88
Die Autoren

Dr. Stefan Lanz (l.) arbeitet als Data Scientist bei BKW Netze, wo er datenbasierte Entscheidungshilfen für den Betrieb und die Planung des Stromnetzes entwickelt.
Dr. Christof Schüpbach (r.) ist Forschungsprogrammleiter bei armasuisse Wissenschaft + Technologie und forscht zur Anwendung von Machine Learning bei der Verarbeitung von Funksignalen.
Beide sind Dozenten im Studiengang Data Science am IBAW. www.ibaw.ch/data-science
Magazin kostenlos abonnieren
Abonnieren Sie das topsoft Fachmagazin kostenlos. 4 x im Jahr in Ihrem Briefkasten.